极客音频:
https://log2x.cn/assets/files/2024-10-24/1729758432-853746-os34.mp3
上一节我们讲了几个重要的 Linux 命令行,只有通过这些命令,用户才能把 Linux 系统用起来,不知道你掌握得如何了?其实 Linux 命令也是一个程序,只不过代码是别人写好的,你直接用就可以了。你可以自己试着写写代码,通过代码把 Linux 系统用起来,这样印象会更深刻。
不过,无论是别人写的程序,还是你写的程序,运行起来都是进程。如果你是一家外包公司,一个项目的运行要使用公司的服务,那就应该去办事大厅,也就是说,你写的程序应该使用系统调用。
你看,系统调用决定了这个操作系统好用不好用、功能全不全。对应到咱们这个公司中,作为一个老板,你应该好好规划一下,你的办事大厅能够提供哪些服务,这决定了你这个公司会被打五星还是打差评。
立项服务与进程管理
首先,我们得有个项目,那就要有立项服务。对应到 Linux 操作系统中就是创建进程。
创建进程的系统调用叫fork。这个名字很奇怪,中文叫“分支”。为啥启动一个新进程叫“分支”呢?
在 Linux 里,要创建一个新的进程,需要一个老的进程调用 fork 来实现,其中老的进程叫作父进程(Parent Process),新的进程叫作子进程(Child Process)。
前面我们说过,一个进程的运行是要有一个程序的,就像一个项目的执行,要有一个项目执行计划书。本来老的项目,按照项目计划书按部就班地来,项目执行到一半,突然接到命令,说是要新启动一个项目,这个时候应该怎么办呢?
一个项目的执行是很复杂的,需要涉及公司各个部门的工作,比如说,项目管理部门需要给这个项目组开好 Jira 和 Wiki,会议室管理部要为这个项目分配会议室等等。
所以,我们现在有两种方式,一种是列一个清单,清单里面写明每个新项目组都要开哪些账号。但是,这样每次有项目,都要重新配置一遍新的 Jira、Wiki,复杂得很。另一种方式就是咱们程序员常用的方式,CTRL/C + CTRL/V。也就是说,如果想为新项目建立一套 Jira,但是觉一个个填 Jira 里面的选项太麻烦,那就可以拷贝一个别人的,然后根据新项目的实际情况,将相应的配置改改。
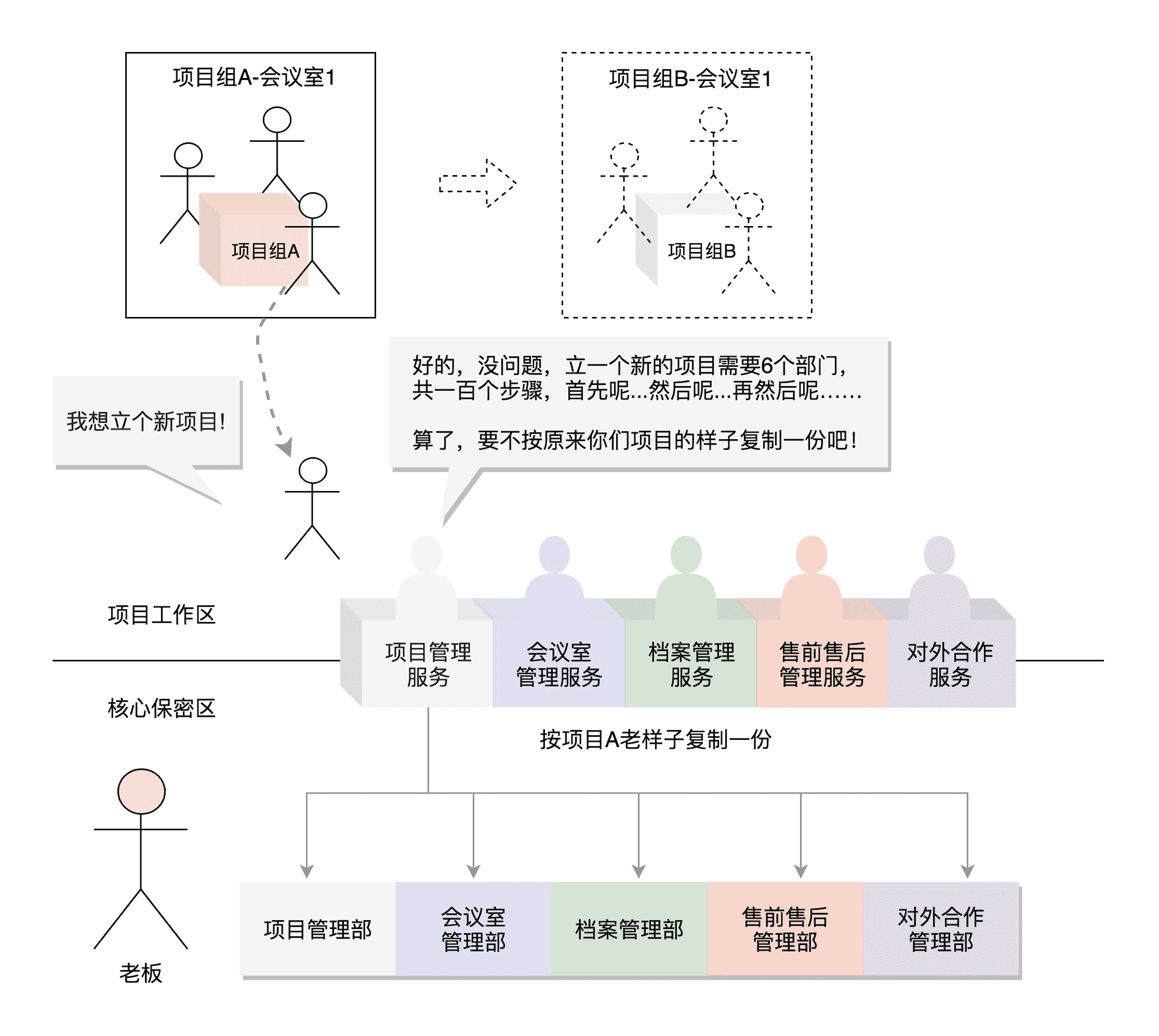
Linux 就是这样想的。当父进程调用 fork 创建进程的时候,子进程将各个子系统为父进程创建的数据结构也全部拷贝了一份,甚至连程序代码也是拷贝过来的。按理说,如果不进行特殊的处理,父进程和子进程都按相同的程序代码进行下去,这样就没有意义了。
所以,我们往往会这样处理:对于 fork 系统调用的返回值,如果当前进程是子进程,就返回 0;如果当前进程是父进程,就返回子进程的进程号。这样首先在返回值这里就有了一个区分,然后通过 if-else 语句判断,如果是父进程,还接着做原来应该做的事情;如果是子进程,需要请求另一个系统调用execve来执行另一个程序,这个时候,子进程和父进程就彻底分道扬镳了,也即产生了一个分支(fork)了。
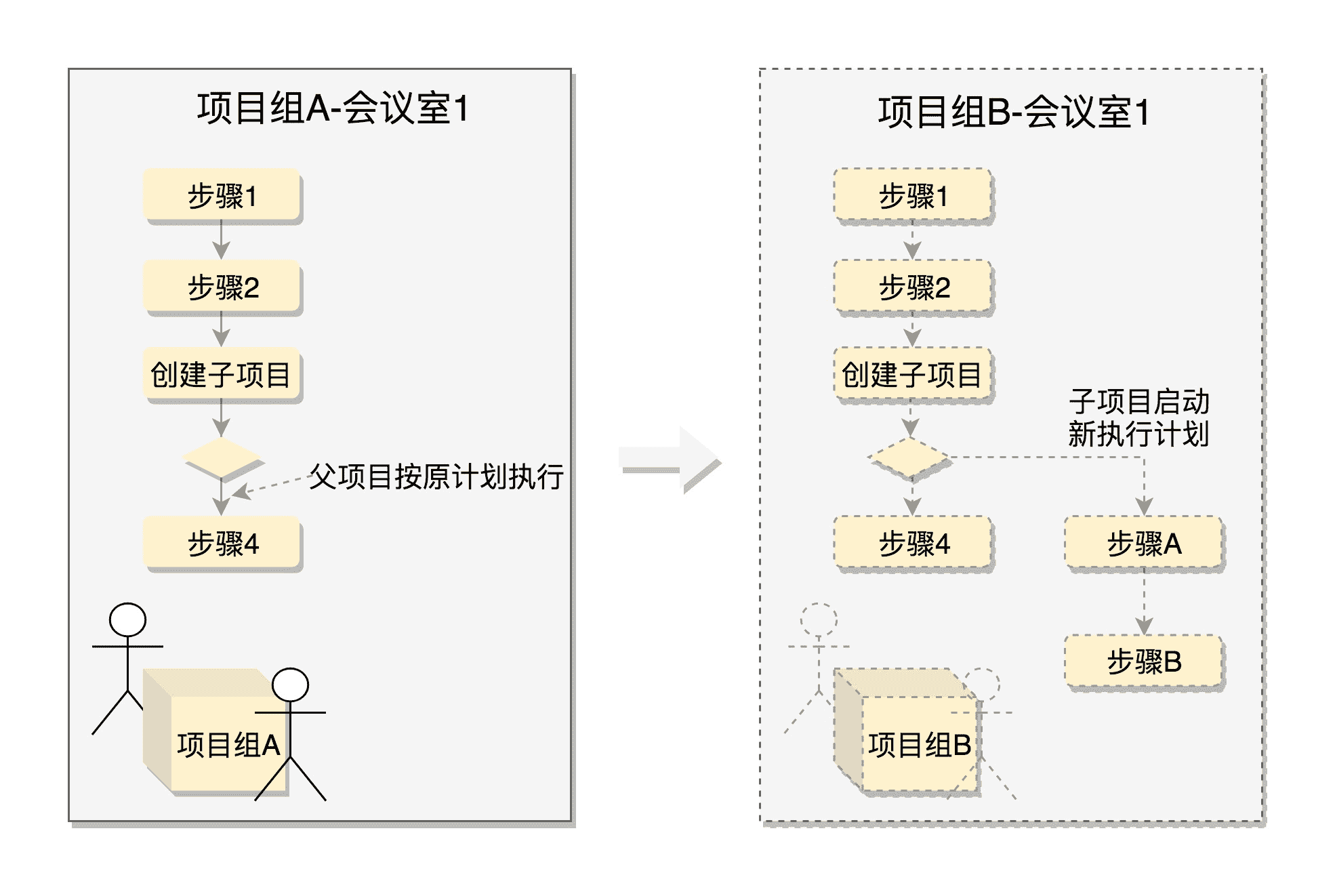
同样是“先拷贝,再修改”的策略,你可能会问,新进程都是父进程 fork 出来的,那到底谁是第一个呢?
作为一个外包公司老板,有了新项目当然会分给手下做,但是当公司刚起步的时候呢?没有下属,只好自己上了。先建立项目运行体系,等后面再做项目的时候,就都按这个来。
对于操作系统也一样,启动的时候先创建一个所有用户进程的“祖宗进程”。这个在讲系统启动的时候还会详细讲,我这里先不多说。
有时候,父进程要关心子进程的运行情况,这毕竟是自己身上掉下来的肉。有个系统调用waitpid,父进程可以调用它,将子进程的进程号作为参数传给它,这样父进程就知道子进程运行完了没有,成功与否。
所以说,所有子项目最终都是老板,也就是祖宗进程 fork 过来的,因而它要对整个公司的项目执行负最终的责任。
会议室管理与内存管理
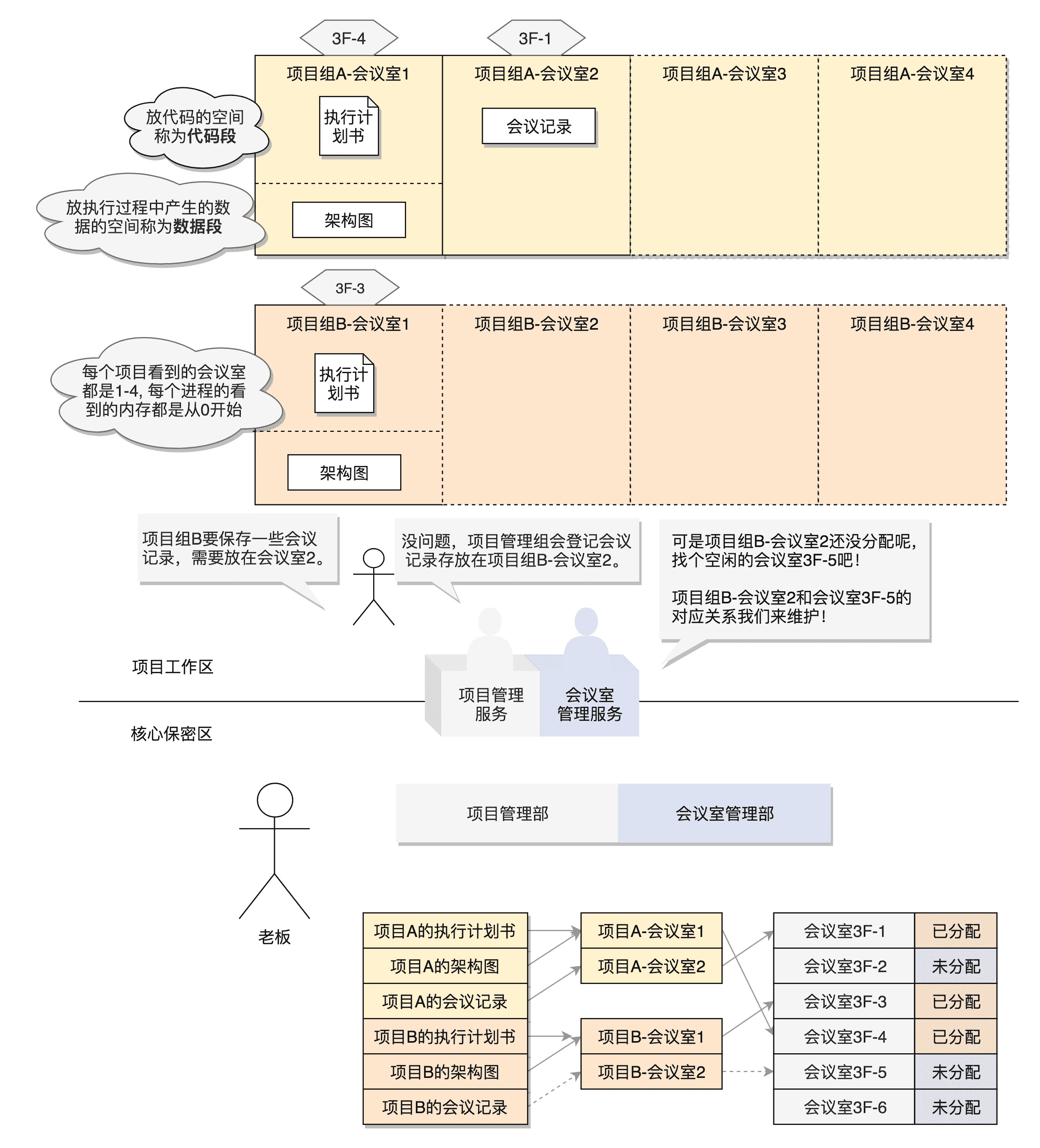
项目启动之后,每个项目组有独立的会议室,存放自己项目相关的数据。每个项目组都感觉自己有独立的办公空间。
在操作系统中,每个进程都有自己的内存,互相之间不干扰,有独立的进程内存空间。
那独立的办公空间里面,都放些什么呢?
项目执行计划书肯定是要放进去的,因为执行过程中肯定要不断地看。对于进程的内存空间来讲,放程序代码的这部分,我们称为代码段(Code Segment)。
项目执行的过程中,会产生一些架构图、流程图,这些也放在会议室里面。有的画在白板上,讨论完了,进入下个主题就会擦了;有的画在纸和本子上,讨论的时候翻出来,不讨论的时候堆在那里,会保留比较长的一段时间,除非指明的确不需要了才会去销毁。
对于进程的内存空间来讲,放进程运行中产生数据的这部分,我们称为数据段(Data Segment)。其中局部变量的部分,在当前函数执行的时候起作用,当进入另一个函数时,这个变量就释放了;也有动态分配的,会较长时间保存,指明才销毁的,这部分称为堆(Heap)。
一个进程的内存空间是很大的,32 位的是 4G,64 位的就更大了,我们不可能有这么多物理内存。就像一个公司的会议室是有限的,作为老板,你不可能事先都给项目组分配好。哪有这么多会议室啊,一定是需要的时候再分配。
所以,进程自己不用的部分就不用管,只有进程要去使用部分内存的时候,才会使用内存管理的系统调用来登记,说自己马上就要用了,希望分配一部分内存给它,但是这还不代表真的就对应到了物理内存。只有真的写入数据的时候,发现没有对应物理内存,才会触发一个中断,现分配物理内存。
这里我们介绍两个在堆里面分配内存的系统调用,brk和mmap。
当分配的内存数量比较小的时候,使用 brk,会和原来的堆的数据连在一起,这就像多分配两三个工位,在原来的区域旁边搬两把椅子就行了。当分配的内存数量比较大的时候,使用 mmap,会重新划分一块区域,也就是说,当办公空间需要太多的时候,索性来个一整块。
档案库管理与文件管理
项目执行计划书要保存在档案库里,有一些需要长时间保存,这样哪怕公司暂时停业,再次经营的时候还可以继续使用。同样,程序、文档、照片等,哪怕关机再开机也能不丢的,就需要放在文件系统里面。
文件之所以能做到这一点,一方面是因为介质,另一方面是因为格式。公司之所以强调资料库,也是希望将一些知识固化为标准格式,放在一起进行管理,无论多少人来人走,都不影响公司业务。
文件管理其实花样不多,拍着脑袋都能想出来,无非是创建、打开、读、写等。
对于文件的操作,下面这六个系统调用是最重要的:
对于已经有的文件,可以使用open打开这个文件,close关闭这个文件;
对于没有的文件,可以使用creat创建文件;
打开文件以后,可以使用lseek跳到文件的某个位置;
可以对文件的内容进行读写,读的系统调用是read,写是write。
但是别忘了,Linux 里有一个特点,那就是一切皆文件。
启动一个进程,需要一个程序文件,这是一个二进制文件。
启动的时候,要加载一些配置文件,例如 yml、properties 等,这是文本文件;启动之后会打印一些日志,如果写到硬盘上,也是文本文件。
但是如果我想把日志打印到交互控制台上,在命令行上唰唰地打印出来,这其实也是一个文件,是标准输出stdout 文件。
这个进程的输出可以作为另一个进程的输入,这种方式称为管道,管道也是一个文件。
进程可以通过网络和其他进程进行通信,建立的Socket,也是一个文件。
进程需要访问外部设备,设备也是一个文件。
文件都被存储在文件夹里面,其实文件夹也是一个文件。
进程运行起来,要想看到进程运行的情况,会在 /proc 下面有对应的进程号,还是一系列文件。
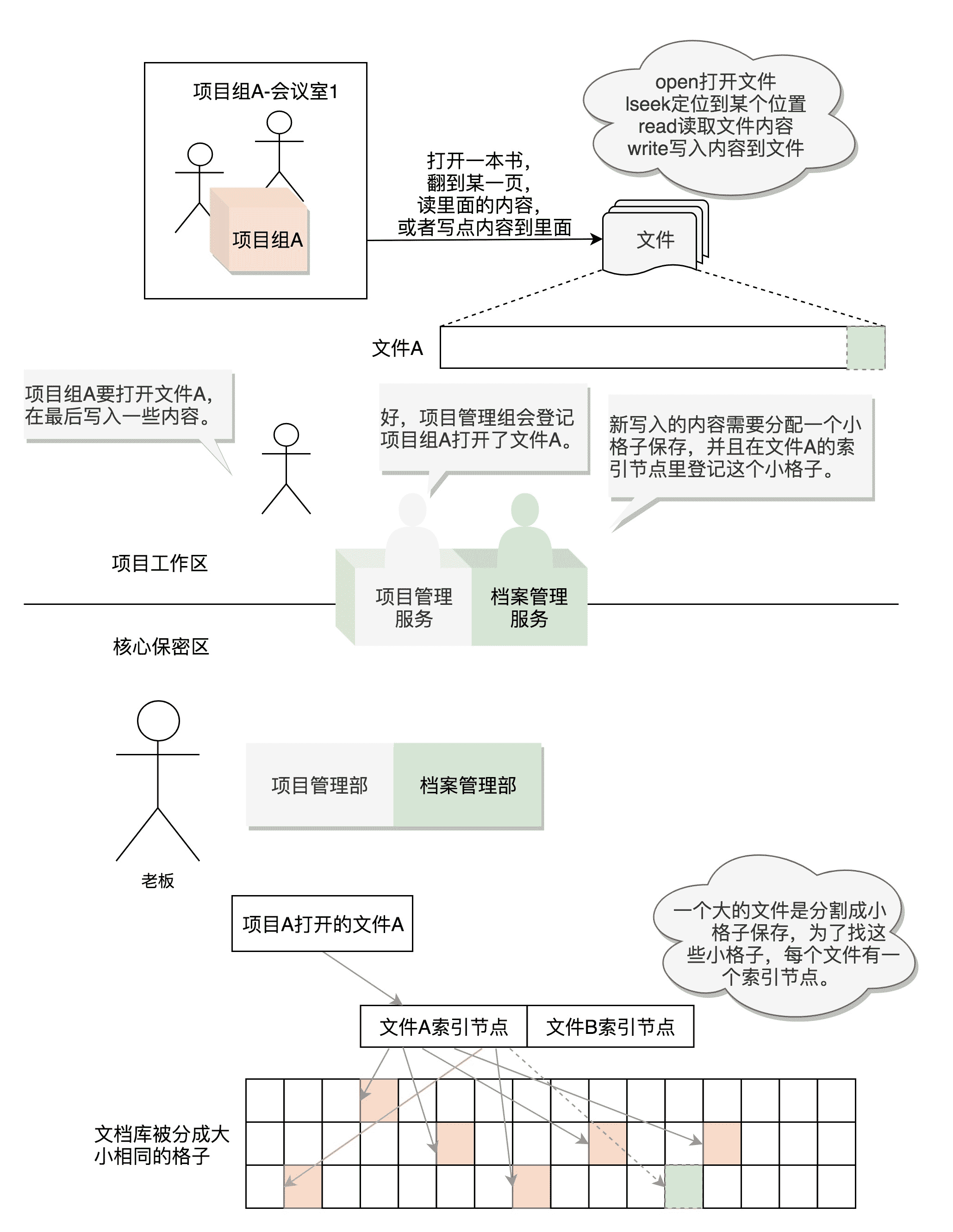
每个文件,Linux 都会分配一个文件描述符(File Descriptor),这是一个整数。有了这个文件描述符,我们就可以使用系统调用,查看或者干预进程运行的方方面面。
所以说,文件操作是贯穿始终的,这也是“一切皆文件”的优势,就是统一了操作的入口,提供了极大的便利。
项目异常处理与信号处理
在项目运行过程中,不一定都是一帆风顺的,很可能遇到各种异常情况。作为老板,处理异常情况的能力是非常重要的,所以办事大厅也一定要包含这部分服务。
当项目遇到异常情况,例如项目中断,做到一半不做了。这时候就需要发送一个信号(Signal)给项目组。经常遇到的信号有以下几种:
在执行一个程序的时候,在键盘输入“CTRL+C”,这就是中断的信号,正在执行的命令就会中止退出;
如果非法访问内存,例如你跑到别人的会议室,可能会看到不该看的东西;
硬件故障,设备出了问题,当然要通知项目组;
用户进程通过kill函数,将一个用户信号发送给另一个进程。
当项目组收到信号的时候,项目组需要决定如何处理这些异常情况。
对于一些不严重的信号,可以忽略,该干啥干啥,但是像 SIGKILL(用于终止一个进程的信号)和 SIGSTOP(用于中止一个进程的信号)是不能忽略的,可以执行对于该信号的默认动作。每种信号都定义了默认的动作,例如硬件故障,默认终止;也可以提供信号处理函数,可以通过sigaction系统调用,注册一个信号处理函数。
提供了信号处理服务,项目执行过程中一旦有变动,就可以及时处理了。
项目组间沟通与进程间通信
当某个项目比较大的时候,可能分成多个项目组,不同的项目组需要相互交流、相互配合才能完成,这就需要一个项目组之间的沟通机制。项目组之间的沟通方式有很多种,我们来一一规划。
首先就是发个消息,不需要一段很长的数据,这种方式称为消息队列(Message Queue)。由于一个公司内的多个项目组沟通时,这个消息队列是在内核里的,我们可以通过msgget创建一个新的队列,msgsnd将消息发送到消息队列,而消息接收方可以使用msgrcv从队列中取消息。
当两个项目组需要交互的信息比较大的时候,可以使用共享内存的方式,也即两个项目组共享一个会议室(这样数据就不需要拷贝来拷贝去)。大家都到这个会议室来,就可以完成沟通了。这时候,我们可以通过shmget创建一个共享内存块,通过shmat将共享内存映射到自己的内存空间,然后就可以读写了。
但是,两个项目组共同访问一个会议室里的数据,就会存在“竞争”的问题。如果大家同时修改同一块数据咋办?这就需要有一种方式,让不同的人能够排他地访问,这就是信号量的机制Semaphore。
这个机制比较复杂,我这里说一种简单的场景。
对于只允许一个人访问的需求,我们可以将信号量设为 1。当一个人要访问的时候,先调用sem_wait。如果这时候没有人访问,则占用这个信号量,他就可以开始访问了。如果这个时候另一个人要访问,也会调用 sem_wait。由于前一个人已经在访问了,所以后面这个人就必须等待上一个人访问完之后才能访问。当上一个人访问完毕后,会调用sem_post将信号量释放,于是下一个人等待结束,可以访问这个资源了。
公司间沟通与网络通信
同一个公司不同项目组之间的合作搞定了,如果是不同公司之间呢?也就是说,这台 Linux 要和另一台 Linux 交流,这时候,我们就需要用到网络服务。
不同机器的通过网络相互通信,要遵循相同的网络协议,也即TCP/IP 网络协议栈。Linux 内核里有对于网络协议栈的实现。如何暴露出服务给项目组使用呢?
网络服务是通过套接字 Socket 来提供服务的。Socket 这个名字很有意思,可以作“插口”或者“插槽”讲。虽然我们是写软件程序,但是你可以想象成弄一根网线,一头插在客户端,一头插在服务端,然后进行通信。因此,在通信之前,双方都要建立一个 Socket。
我们可以通过 Socket 系统调用建立一个 Socket。Socket 也是一个文件,也有一个文件描述符,也可以通过读写函数进行通信。
好了,我们分门别类地规划了这么多办事大厅的服务,如果这些都有了,足够我们成长为一个大型跨国公司了。
查看源代码中的系统调用
你如果问,这里的系统调用列举全了吗?其实没有,系统调用非常多。我建议你访问https://www.kernel.org下载一份 Linux 内核源代码。因为在接下来的整个课程里,我讲述的逻辑都是这些内核代码的逻辑。
对于 64 位操作系统,找到 unistd_64.h 文件,里面对于系统调用的定义,就是下面这样。
#define __NR_restart_syscall 0
#define __NR_exit 1
#define __NR_fork 2
#define __NR_read 3
#define __NR_write 4
#define __NR_open 5
#define __NR_close 6
#define __NR_waitpid 7
#define __NR_creat 8
......
中介与 Glibc
如果你做过开发,你会觉得刚才讲的和平时咱们调用的函数不太一样。这是因为,平时你并没有直接使用系统调用。虽然咱们的办事大厅已经很方便了,但是为了对用户更友好,我们还可以使用中介Glibc,有事情找它就行,它会转换成为系统调用,帮你调用。
Glibc 是 Linux 下使用的开源的标准 C 库,它是 GNU 发布的 libc 库。Glibc 为程序员提供丰富的 API,除了例如字符串处理、数学运算等用户态服务之外,最重要的是封装了操作系统提供的系统服务,即系统调用的封装。
每个特定的系统调用对应了至少一个 Glibc 封装的库函数,比如说,系统提供的打开文件系统调用 sys_open 对应的是 Glibc 中的 open 函数。
有时候,Glibc 一个单独的 API 可能调用多个系统调用,比如说,Glibc 提供的 printf 函数就会调用如 sys_open、sys_mmap、sys_write、sys_close 等等系统调用。
也有时候,多个 API 也可能只对应同一个系统调用,如 Glibc 下实现的 malloc、calloc、free 等函数用来分配和释放内存,都利用了内核的 sys_brk 的系统调用。
总结时刻
学了这么多系统调用,我们还是用一个图来总结一下。
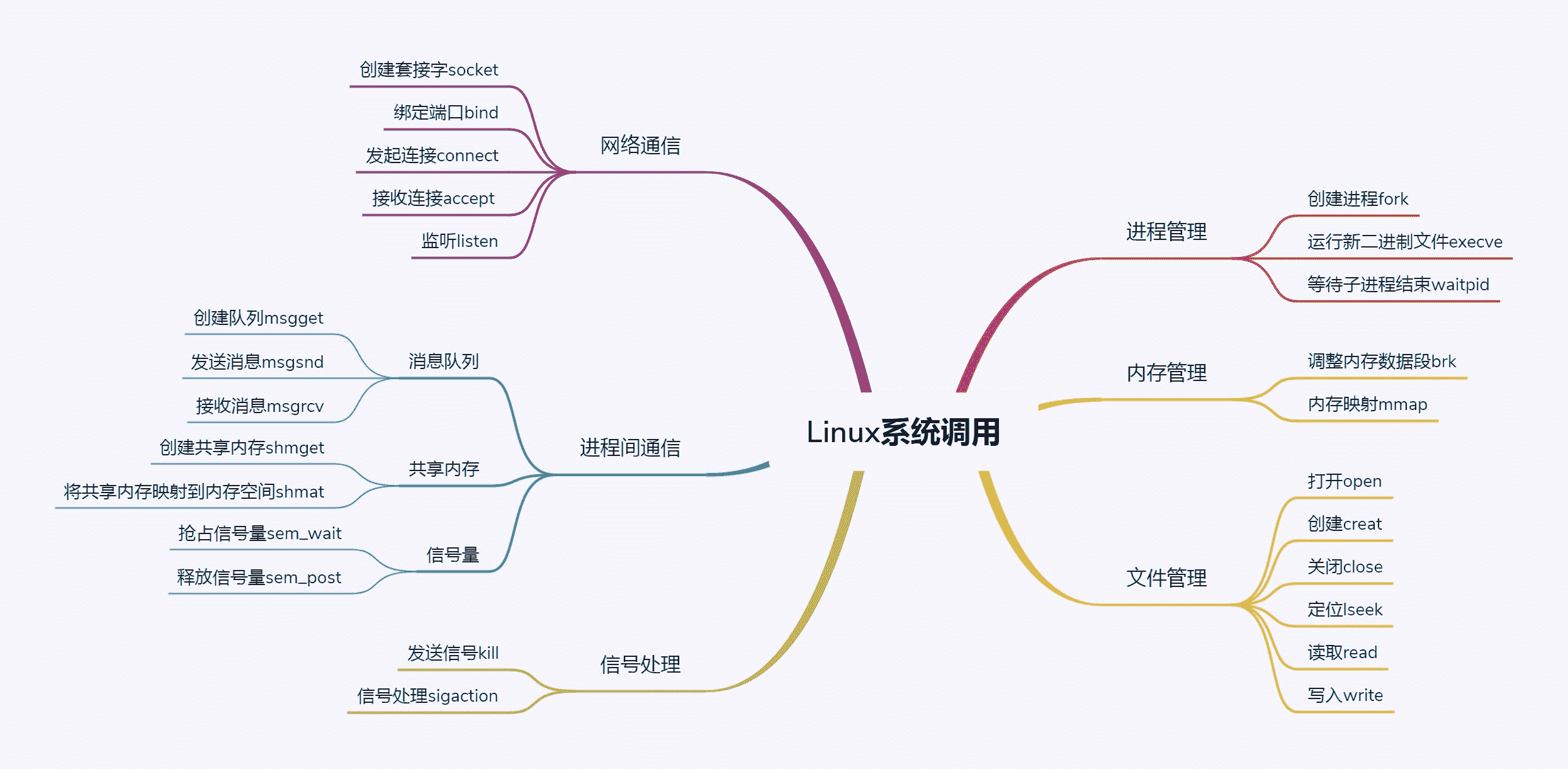
课堂练习
有个命令 strace,常用来跟踪进程执行时系统调用和所接收的信号。你可以试一下咱们学过的命令行,看看都执行了哪些系统调用。
欢迎留言和我分享你的疑惑和见解,也欢迎你收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习、进步。